从 2017 年到今天不到 10 年,AI 从"看不懂一句话"进化到"能替你写报告"。
速度还在加快。
2.1 大语言模型
大语言模型(LLM)到底是什么?
先看看 AI 是怎么"进化"到今天的——不到 10 年,从"看不懂一句话"到"能替你写报告"
📅
LLM 进化时间线——从规则到智能
1950s - 1990s
规则系统 & 统计模型
AI 靠人工写规则 + 统计概率工作,像"查字典"
2003
神经网络语言模型(Bengio)
第一次让 AI 用"大脑"理解词语之间的关系
⭐ 2017 · 一切的起点
Transformer 架构诞生
Google 8 位科学家发表《Attention is All You Need》,奠定了今天所有大模型的基础架构
2018
BERT & GPT-1 —— 两大流派诞生
BERT 擅长"理解"(完形填空),GPT 擅长"生成"(续写文章)
2020
GPT-3(1750 亿参数)
第一次让人惊呼"AI 会写文章了"——训练成本约 460 万美元
⭐ 2022.11 · AI 的 iPhone 时刻
ChatGPT 发布
让普通人第一次能跟 AI 自然对话。5 天用户破百万,2 个月破 1 亿
2023.3
GPT-4(多模态)
能同时理解文字、图片、语音,综合能力大幅跃升
2024
多模态成熟 · 成本骤降
GPT-4o、Claude 3.5、Gemini 2.0——推理能力大幅提升,价格断崖式下降
🇨🇳 2025.1 · 中国开源崛起
DeepSeek-R1 发布
性能比肩 GPT-4,训练成本仅 1/10~1/20,完全开源,震动全球 AI 行业
2025 - 2026 · 我们正处于这里
Agent 爆发之年
Claude 4、GPT-5、Gemini 2.5 Pro——推理接近人类专家,AI 从"聊天"变成"做事"
🧠
LLM 核心原理——用大白话讲清楚
一句话解释 LLM:
读了互联网上几乎所有文章的
"超级语言接龙选手"
Transformer 架构(简化版)——AI 读文字的三个步骤
1
🧩 Token 化(拆成积木块)
苹果
公司
发布
了
新
手机
AI 看到的不是"字",而是积木块(Token)。中文一个字 ≈ 1-2 个 Token
2
👀 注意力机制(Attention)
苹果 ← ━━━ 强关联 ━━━ → 公司
苹果 ← ── 中关联 ── → 手机
AI 同时看所有词之间的关系 → 理解"苹果"是公司而非水果
3
🎲 预测下一个词(概率接龙)
"苹果公司发布了新手机,该手机..."
配备
搭载
采用
💡 类比:就像手机输入法的"联想词"功能——但复杂度高几个数量级。AI 选的是"概率最高的词",而非"事实正确的词"。
🌡️ Temperature(温度)—— AI 的"冒险精神旋钮"
🧊 Temperature = 0(保守)
"今天天气晴朗,适合出行。"
总选概率最高的词
适合:写报告、做数据分析
🔥 Temperature = 1(创意)
"今天的阳光像个热情的老朋友,非得拉你出去溜达不可。"
愿意选概率稍低的词
适合:头脑风暴、写文案
🔬
Transformer 架构进阶详解——给想深入了解的同学
📄 开山论文:《Attention Is All You Need》
2017 年,Google 的 8 位研究员(Vaswani 等人)发表了这篇论文,提出了 Transformer 架构。它完全抛弃了此前 NLP 领域主流的 RNN/LSTM 循环结构,仅靠注意力机制(Attention)就实现了更好的效果和更快的训练速度。
此后所有大语言模型——GPT 系列、BERT、LLaMA、DeepSeek——都基于 Transformer 架构或其变体。
📐 整体架构:Encoder-Decoder
原始 Transformer 由两部分组成:编码器(Encoder)负责"理解"输入,解码器(Decoder)负责"生成"输出。但今天的主流 LLM(如 GPT 系列)只用了 Decoder 部分。
输入文本: "苹果公司发布了新手机"
│
▼
┌──────────────────────────────────────┐
│ ① Token 化 + 位置编码 │
│ "苹果" → [0.23, -0.15, ...] │
│ 每个 Token 变成一个高维向量 │
│ + 加入位置信息(第几个词) │
└──────────────┬───────────────────────┘
│
┌────────────▼────────────┐
│ ② 多头自注意力 × N 层 │ ← 核心!下面详细讲
│ (Multi-Head Attention) │
│ + 前馈神经网络 (FFN) │
│ + 残差连接 + 层归一化 │
│ × 重复 N 次(GPT-3: 96层)│
└────────────┬────────────┘
│
┌────────────▼────────────┐
│ ③ 输出概率分布 │
│ Softmax → 词表中每个 │
│ Token 的概率 │
│ 选概率最高的 → 输出 │
└─────────────────────────┘
1️⃣ 词嵌入(Embedding)+ 位置编码(Positional Encoding)
词嵌入:每个 Token 被映射成一个高维向量(如 768 维或 12288 维),语义相近的词在向量空间中距离也更近。
"国王" - "男人" + "女人" ≈ "王后"
词向量可以做语义运算——这是 AI "理解"语言的基础
位置编码:Transformer 不像 RNN 那样按顺序处理文字,它是并行处理所有 Token 的。这就需要额外加入位置信息,告诉模型"苹果"是第 1 个词、"公司"是第 2 个词。
原始论文用正弦/余弦函数编码位置;现代模型(如 LLaMA)多用旋转位置编码(RoPE),能更好地处理超长文本。
2️⃣ 自注意力机制(Self-Attention)—— Transformer 的灵魂
自注意力的核心思想:对于每个词,计算它和句子中所有其他词的关联程度,然后用这个关联程度来加权整合信息。
Q、K、V 三大矩阵:
Q
Query(查询)
"我想找什么信息?"
当前词要问的问题
K
Key(键)
"我有什么信息?"
每个词的索引标签
V
Value(值)
"我实际的内容"
每个词携带的语义
计算公式:
Attention(Q, K, V) = softmax(QKT / √dk) · V
① QKT:计算每对词之间的"相关性得分"(点积)
② ÷ √dk:缩放,防止得分过大导致梯度消失(dk 是向量维度)
③ softmax:将得分转化为概率分布(所有注意力权重加和 = 1)
④ · V:用注意力权重对 Value 加权求和,得到融合了上下文信息的新表示
💡 类比:你在图书馆找资料。Q 是你的搜索关键词,K 是每本书的标签,V 是书的内容。你用关键词匹配标签(QKT),找到最相关的几本书,然后综合它们的内容(加权 V)得出答案。
3️⃣ 多头注意力(Multi-Head Attention)
不只用一组 Q/K/V,而是同时用多组("多头"),每组关注不同维度的语义关系:
Head 1
关注语法关系
主语-谓语-宾语
Head 2
关注语义相似
"苹果"↔"公司"
Head 3
关注位置距离
近距离词更相关
Head N
关注指代消解
"它"指代什么
GPT-3 有 96 个注意力头,每个头独立计算注意力,最终拼接起来通过线性变换融合。这就像一个团队从多个角度同时分析同一句话。
4️⃣ 前馈网络(FFN)+ 残差连接 + 层归一化
每一层 Transformer Block 包含两个子层:
输入 x
→ LayerNorm(x)
→ Multi-Head Attention → + x ← 残差连接
→ LayerNorm
→ FFN (两层全连接 + 激活函数) → + x ← 残差连接
→ 输出
FFN
对每个位置独立做非线性变换,"消化"注意力收集的信息
残差连接
把输入直接加到输出上,防止深层网络梯度消失
层归一化
稳定训练过程,加速收敛
5️⃣ 两大流派:GPT(自回归) vs BERT(双向)
6️⃣ 规模定律(Scaling Laws)——为什么"大力出奇迹"
OpenAI 在 2020 年发现了Scaling Laws:模型性能与三个因素呈幂律关系——
🧠
参数量 (N)
GPT-3: 1750亿
GPT-4: 传闻 1.8万亿
📚
数据量 (D)
GPT-3: 3000亿 Token
LLaMA 3: 15万亿 Token
⚡
算力 (C)
GPT-4 训练成本
估计超 1 亿美元
三者按比例同步扩大,模型性能就会可预测地持续提升。这就是为什么各大公司都在疯狂堆算力、堆数据——因为"大力出奇迹"在数学上是被验证过的。但 DeepSeek 也证明了:更聪明的架构设计可以用更少的资源达到相近的效果。
📊 主流模型架构参数对比
| 模型 | 参数量 | 层数 | 注意力头 | 隐藏维度 | 上下文 |
|---|---|---|---|---|---|
| GPT-3 | 175B | 96 | 96 | 12,288 | 4K |
| LLaMA 3 | 405B | 126 | 128 | 16,384 | 128K |
| DeepSeek-V3 | 671B (MoE) | 61 | 128 | 7,168 | 128K |
| GPT-5 | 未公开 | 未公开 | 未公开 | 未公开 | 256K |
* MoE = Mixture of Experts(混合专家),DeepSeek 每次推理只激活约 37B 参数,大幅降低成本
🧩
Token——AI 的最小阅读单位
AI 看到的不是一个个"字",而是一块块"积木"。每块积木叫一个 Token。
📐 Token 效率对比:
中文
1 个字 ≈ 1-2 个 Token
English
1 个词 ≈ 1 个 Token
这也解释了:为什么中文 AI 要比英文贵?为什么 AI 数不对中文字数?
📍 现场演示:看看 AI 怎么"拆字"
用 Tiktokenizer 看看"四中十五班AI培训"在 AI 眼里长什么样——
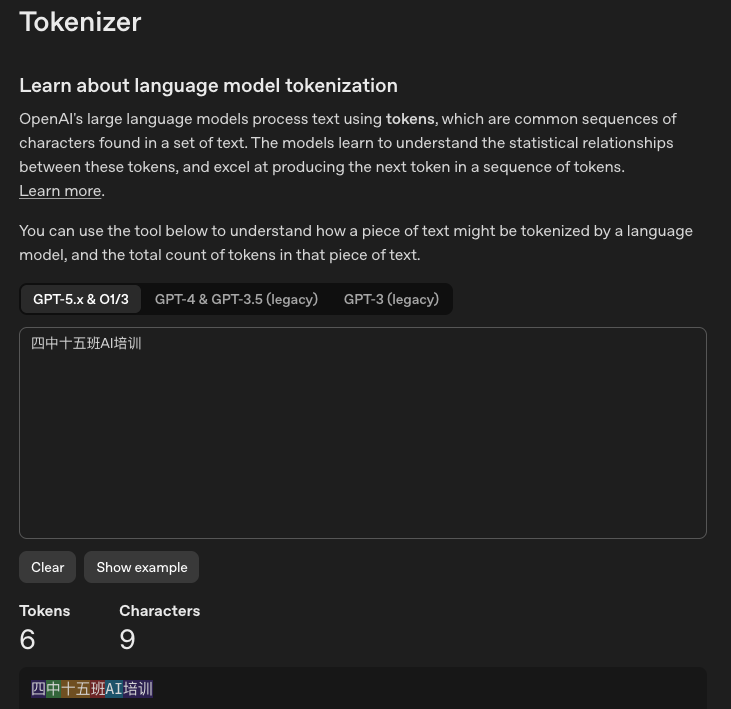
🔤 "四中十五班AI培训"(中文)
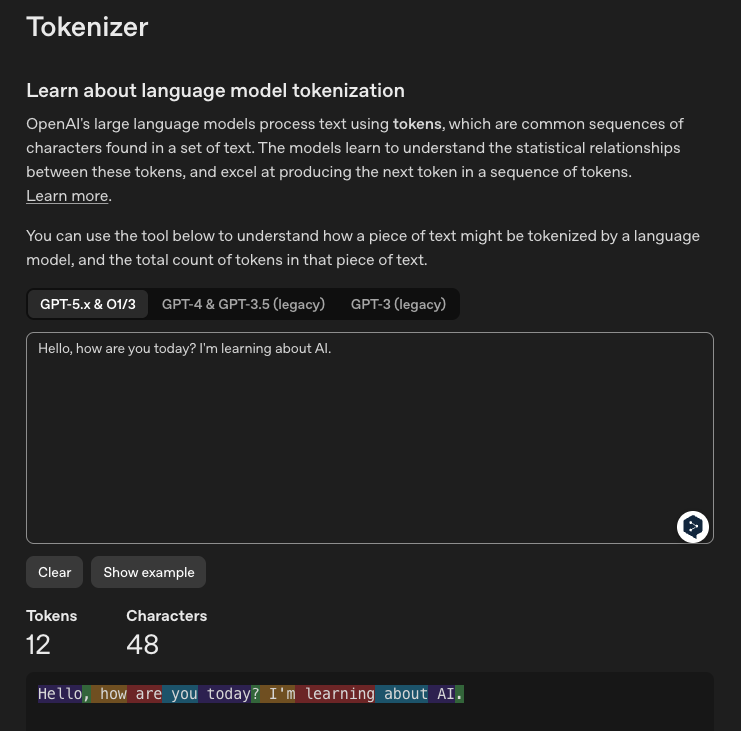
🔤 英文分词示例(GPT-5.x)
💡 同一句话,中文 vs 英文、新模型 vs 旧模型,Token 数量差异巨大:
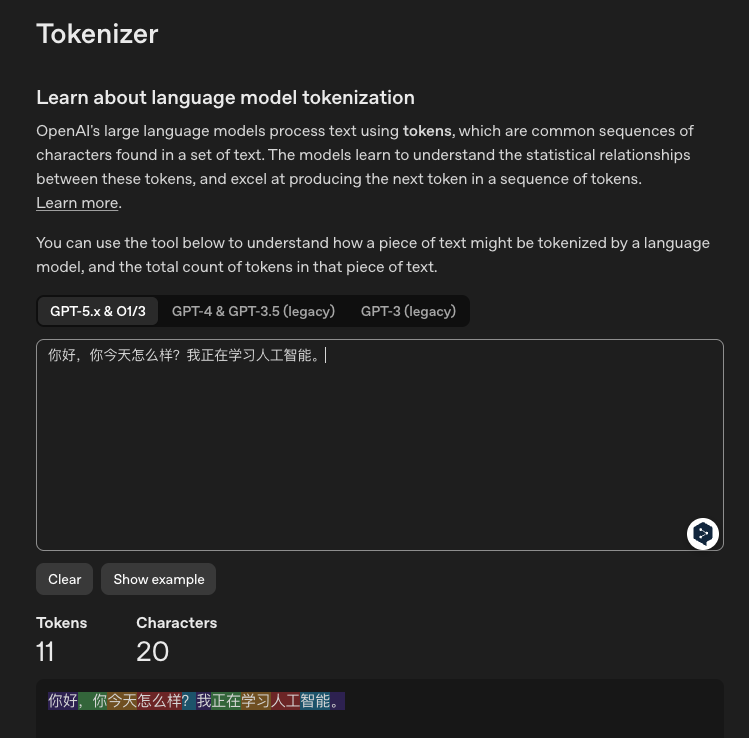
中文 · GPT-5.x(11 Tokens)
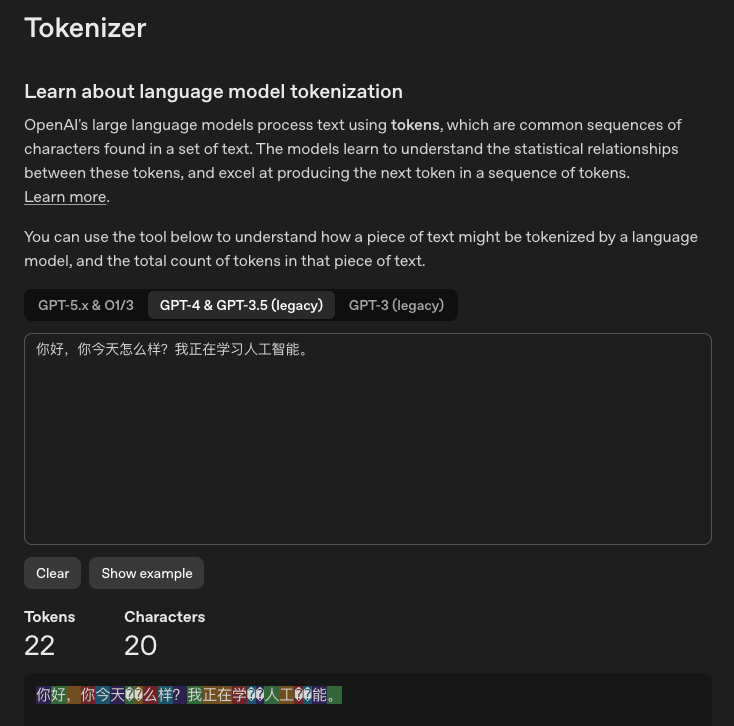
中文 · GPT-4(22 Tokens ⚠️ 翻倍!)
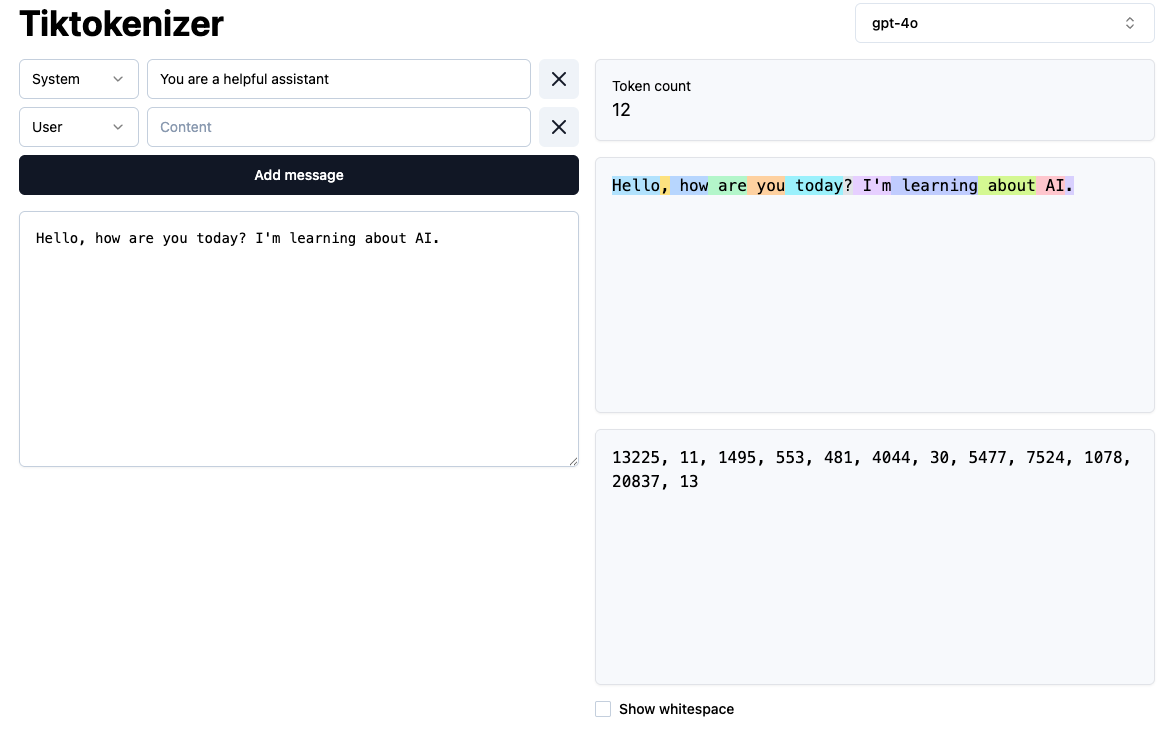
英文 · Tiktokenizer(12 Tokens)
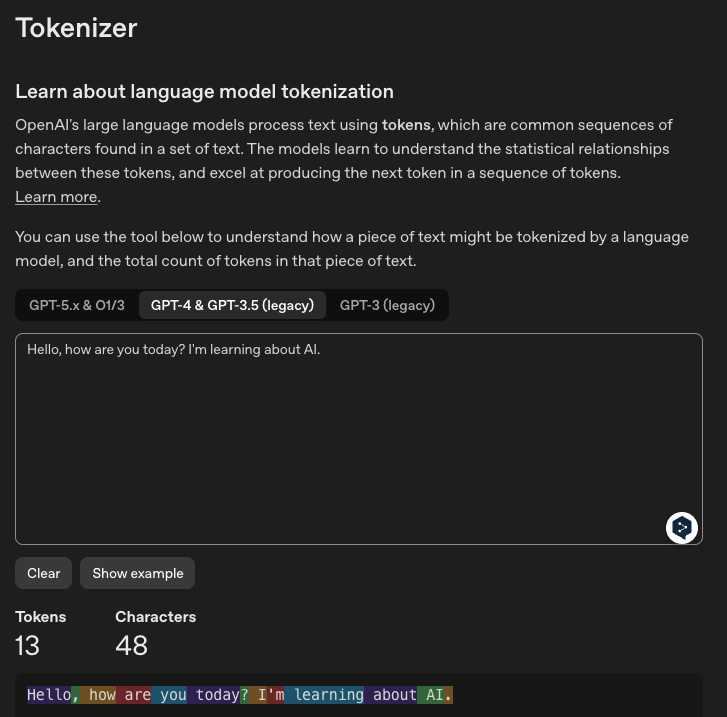
英文 · GPT-4(13 Tokens)
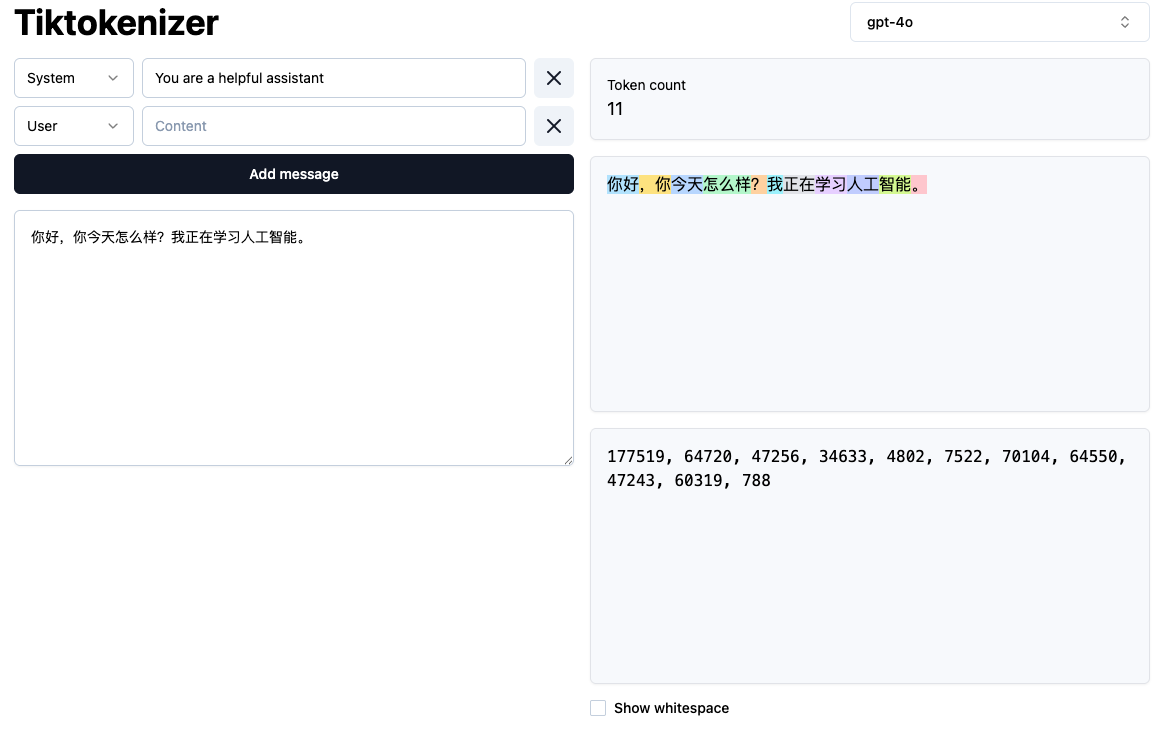
中文 · Tiktokenizer(11 Tokens)
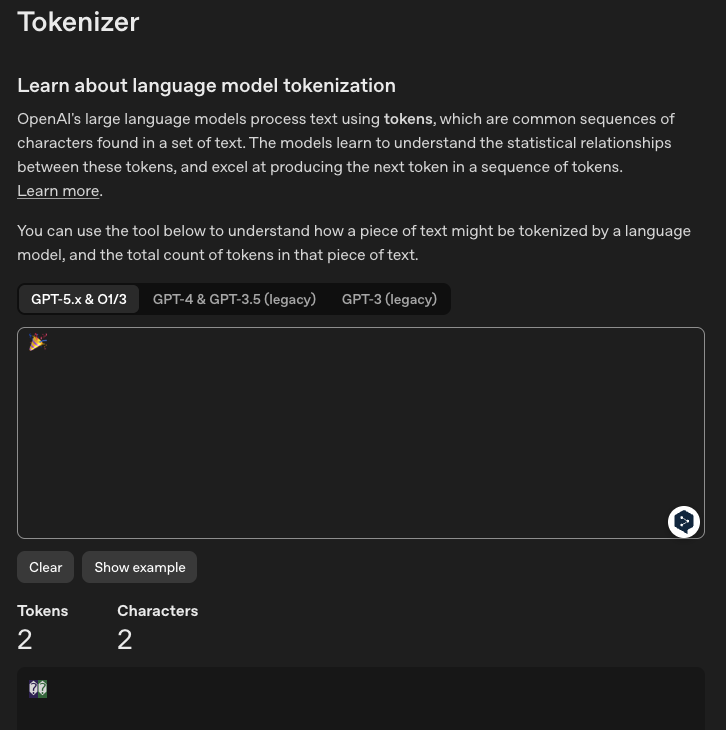
🎉 Emoji 也是 Token(2 Tokens)
💡 回顾翻车#2(倒写文字):现在你理解了——AI 是按 Token(积木块)处理文字的,它根本"看不见"单个汉字的顺序。让它倒写文字,就像让你蒙着眼拆拼图。
📌 关键概念扫盲
三个必须知道的核心概念
理解了这三个概念,你就能看懂 90% 的 AI 新闻
1
🎓 训练 vs 推理——AI 的"上学"和"工作"
🎓 训练(Training)= 上学
花几个月,读完半个互联网
📚 数据量:万亿级 Token(相当于数百万本书)
💰 成本:数千万 ~ 数亿美元
⏱️ 耗时:几周到几个月
🖥️ 硬件:数千张 GPU 并行
训练完成后,AI 的"知识"就固定了——
这就是为什么 AI 有"知识截止日期"
📝 推理(Inference)= 工作
你每次提问,它用学到的知识回答
⚡ 速度:几秒到几十秒
💰 成本:每次几分钱到几毛钱
🖥️ 硬件:1 张 GPU 即可
👤 就是你每天用 ChatGPT 的过程
你不是在"训练" AI,你只是在"考试"——
它不会因为你的提问而变聪明
💡 一句话记住:训练 = 花几个亿让 AI 读完互联网(你付不起);推理 = 花几分钱让 AI 回答你的问题(你天天在用)
2
📏 上下文窗口——AI 的"短期记忆"
上下文窗口 = AI 一次对话中能"记住"多少内容。就像人的工作台:台子越大,能同时摊开的资料越多。
各主流模型的上下文窗口大小(2025-2026):
GPT-4128K
Claude 3.5200K
⬇️ 2025-2026 最新一代
GPT-5256K
Claude Opus 4.61M
Gemini 2.5 Pro2M 🤯
💡 1M Token 到底有多大?换算成你熟悉的东西:
📚
~8 本书
每本约 300 页
💻
~7.5 万行代码
约一个中型项目
🎬
~10 小时视频字幕
约 5 部电影的台词
🖼️
~1,000 张图片
多模态模型可混合处理
📄
~2,500 页 PDF
一次读完整本合同/手册
📐 上下文在对话中会"越聊越大"
每次你发消息,AI 需要把整段对话历史 + 你的新问题 + 它的回答全部放进上下文窗口。
所以一段对话聊得越久,占用的上下文就越大:第 1 轮可能只用了 1K → 第 10 轮可能已经用了 20K → 聊到 50 轮就可能接近窗口上限。
一旦超出窗口,最早的对话就被"挤掉"了——这就是 AI 会"失忆"的根本原因。
3
👻 幻觉(Hallucination)——AI 最大的"坑"
AI 的幻觉不是"故意骗你",而是由它的底层工作原理必然导致的。理解了原理,你就知道为什么幻觉无法彻底消除。
🔍 先看现象:同一个 AI,两种表现
✅ 训练数据中大量出现
❓ "中国最高的山是?"
→ "珠穆朗玛峰" ✅
"珠穆朗玛峰"紧跟"中国最高的山"出现了无数次
❌ 训练数据中从未出现
❓ "十五班最出名的校友是?"
→ AI 会编一个! ❌
没见过,但"最出名的校友是 XXX"这种句式太常见了
🧠 底层原因:为什么幻觉是"必然"的?
回顾前面讲的 LLM 核心原理——幻觉的三个根因就藏在里面:
⚠️ 哪些场景最容易踩坑?
📊 具体数据和数字
"XX 公司去年营收多少"——AI 经常编数字
📚 引用和来源
"请给出论文出处"——AI 会编造看起来真实的引用
🕐 实时信息
"今天的股价"——AI 的知识有截止日期
👤 小众人物/事件
"XX 小区的物业电话"——训练数据中几乎没有
一句话总结幻觉的本质:
AI 的目标是"生成读起来通顺的文本"
而不是"输出事实正确的信息"
幻觉不是 bug,而是概率生成机制的必然副产品。
模型越强,幻觉越少——但无法彻底消除。
这就是为什么模块一反复强调 Human in the Loop:
AI 输出的内容,涉及事实、数据、专业判断的部分,必须人工验证。
2.1 小结:三个关键认知
🎲
接龙选手
LLM 本质是"预测下一个最可能的词"
🧩
Token 视角
AI 看到的是积木块,不是字和词
👻
概率 ≠ 真相
概率最高的不等于事实正确
Section 2.2
✍️ Prompt 工程
跟 AI 说话的科学——同样的需求,不同 Prompt 效果天差地别
2.2 Prompt 工程
为什么你问不出好答案?
让我们用同一个需求,分三轮测试——看看 Prompt 的力量
Round 1
随便问一句(7 个字)
Prompt帮我写个工作汇报

🤖 AI 的回答❌ 泛泛而谈
结果:千篇一律的模板,完全不贴合你的实际情况
Round 2
结构化提问(~150 字)
Prompt我需要写一份 2025 年度个人工作汇报,请帮我撰写。
背景信息:
- 我是一家互联网公司的产品经理
- 今年主要负责了公司 App 的 3.0 大版本改版
- 关键成果:DAU 从 50 万提升到 80 万,用户好评率从 3.8 提升到 4.6
- 团队:带领 5 人产品小组
- 挑战:改版初期用户投诉量激增,通过用户调研和快速迭代解决
要求:
- 800 字左右
- 语气专业但不过于正式
- 分为"核心成果"、"重点项目"、"问题与反思"、"明年规划"四个部分
- 突出数据和具体成果

🤖 AI 的回答⚡ 质量大幅提升
结果:有数据、有结构,基本可用,但风格还不够个性化
Round 3
顶级 Prompt(~350 字,用公式)
Prompt# 角色
你是一位在互联网行业工作 15 年的资深产品总监,擅长撰写高质量的工作汇报。你的汇报风格以数据驱动、逻辑清晰、重点突出著称。
# 任务
请帮我撰写一份 2025 年度个人工作汇报。
# 背景信息
- 我是一家互联网公司的产品经理
- 今年主要负责了公司 App 的 3.0 大版本改版
- 关键成果:DAU 从 50 万提升到 80 万(+60%),用户好评率从 3.8 提升到 4.6(+21%)
- 团队:带领 5 人产品小组
- 挑战:改版初期用户投诉量激增 300%,通过 3 轮用户调研 + 敏捷迭代,2 周内将投诉量降至改版前水平
- 额外贡献:建立了产品需求优先级评估框架,被其他 3 个产品线采用
# 输出要求
- 800 字左右,分为四个部分,每部分有小标题
- 每个重点成果用【数据对比】的方式呈现
- 语气:自信但不自夸,专业且有温度
# 参考风格
"Q3 我们将搜索功能的响应时间从 1.2s 优化至 0.3s,直接带动搜索转化率提升 18%。"
请按以上要求撰写,先列出提纲让我确认。

🤖 先生成提纲✅ 专业级输出

🤖 最终报告✅ 几乎可直接使用
结果:数据驱动、风格匹配、先提纲后正文——这就是好 Prompt 的力量
⭐ Prompt 万能公式——五个要素
把这五个要素写清楚,你的 Prompt 水平就能超越 90% 的人
🎭
角色
你是谁
给 AI 一个身份,它会调整专业程度和表达方式
📋
背景
上下文
你的情况、项目信息、限制条件——越具体越好
🎯
任务
要做什么
明确告诉 AI 要做什么,一次只给一个核心任务
📏
要求
怎么做
字数、语气、风格、侧重点等约束条件
📄
格式
最终形式
要表格、要分段、要 Markdown?提前说清楚
核心思路:不是"问 AI 一个问题",而是"给 AI 布置一项任务"
信息给得越充分,结果越符合预期
🚀 进阶技巧
📚
Few-shot(给 AI 看"参考答案")
给 AI 看几个你满意的范例,它就会模仿风格和格式。就像给新员工看"照着这个水平来"。
💡 用法:在 Prompt 结尾加上 # 参考风格 + 示例文本
🔗
Chain of Thought(让 AI "想清楚再说")
加一句"请一步步分析",AI 会显式展示推理过程,大幅减少逻辑错误。
💡 魔法咒语:「请一步一步思考」/ 「Let's think step by step」
🔄
迭代追问(调教 AI)
第一次不满意?不要重新写 Prompt,在同一对话中追问修改。AI 会保持上下文。
💡 口诀:不要推翻重来,而是逐步精调
🙋 动手时间(5 分钟)
用刚学的"五要素公式"(角色+背景+任务+要求+格式),改写下面一个 Prompt,用你的 AI 试试效果
✉️
请假邮件
"帮我写封请假邮件"
✈️
旅行文案
"帮我写个朋友圈文案"
💪
减肥计划
"帮我制定减肥计划"
Prompt 的核心不是"技术",而是"把需求说清楚"
你给 AI 的信息越充分、越结构化,它回答的质量就越高
你给 AI 的信息越充分、越结构化,它回答的质量就越高
—— 这条规律对所有 AI 工具都适用
📝 Part 2 小结
模块二上半场的五个关键收获
📅
AI 不到 10 年
从看不懂文字到写报告
🎲
概率接龙
LLM = 预测下一个词
🧩
Token 视角
AI 看的是积木块不是字
👻
幻觉本质
概率最高 ≠ 事实正确
✍️
五要素公式
角色+背景+任务+要求+格式
接下来 →
模块二下半场:AI Agent + 前沿方向
从"聊天机器人"到"能帮你做事的 AI 同事"
↓